“Works on my machine” issues - Managing dependencies in data teams is painful. It involves getting the right Python packages installed and versions correct, and even working out how to connect to git. Package and environment management libraries like Conda can be helpful, but they don't fully eliminate the need for development environment troubleshooting.
“Processing power” - Data work requires access to substantial memory and processing power. Data teams often turn to their laptops to meet these needs. However, they frequently meet hard limitations such as insufficient RAM, slow processing speed, or inadequate storage that will impact their ability to perform data work.
About Luminus
Luminus is the second largest electricity producer and energy supplier in Belgium. They serve approximately 1.8 million private and professional customers operating across gas-fired power plants, wind farms, and hydraulic power stations.As of January 2024, Luminus has around 2,000 employees. 50 of those employees work on their data team, 40 of which are Gitpod users. One of those data engineers is Jelle De Vleminck. Jelle is the lead platform engineer focused on enabling data engineers and came to Gitpod to solve the problems associated with ‘works on my machine’ and ‘processing power’ issues.
Their technology:
- Infrastructure
- S3 for data storage, configured with VPC endpoints for ensuring users cannot download data on personal devices.
- Snowflake for data warehouse.
- Data stack
- Python, PySpark, AWS, Snowflake, Jupyter Notebooks, VS Code and Gitpod
Python dependency issues
Jelle is part of a platform engineering team that enables the Luminus data engineers. He’s contracted from a consultancy called DataMinded that is focused on helping data engineering teams, including data scientists and data analysts, architect their data platforms, data pipelines and analytics applications.To avoid the overwhelming interface of Amazon SageMaker, Luminus created a custom self-service landing page for their data teams, with environment and image size selection. This was integrated into their data platform allowing their data team to spin up Jupyter Notebooks in Amazon SageMaker. However, due to long startup times, they would wait five minutes to start up each of their notebooks. The teams soon were complaining about the experience."We're a platform team. Our goal is to help other data teams be productive. When you're 30 data engineers, support takes up all the data platform team's time.”
Luminus were also struggling with inconsistent environments within the AWS SageMaker platform; when Amazon would change the underlying platform, the data team would find themselves again stuck with broken environments. Onboarding new data team members, and ensuring their laptops had the right Python versions was time consuming for the data platform team.
"Amazon constantly changes the underlying infrastructure and the way they set it up. Sometimes you have to call pip then pip3 and then the Python version changes and that SageMaker lifecycle configuration script constantly breaks. It was a burden.”
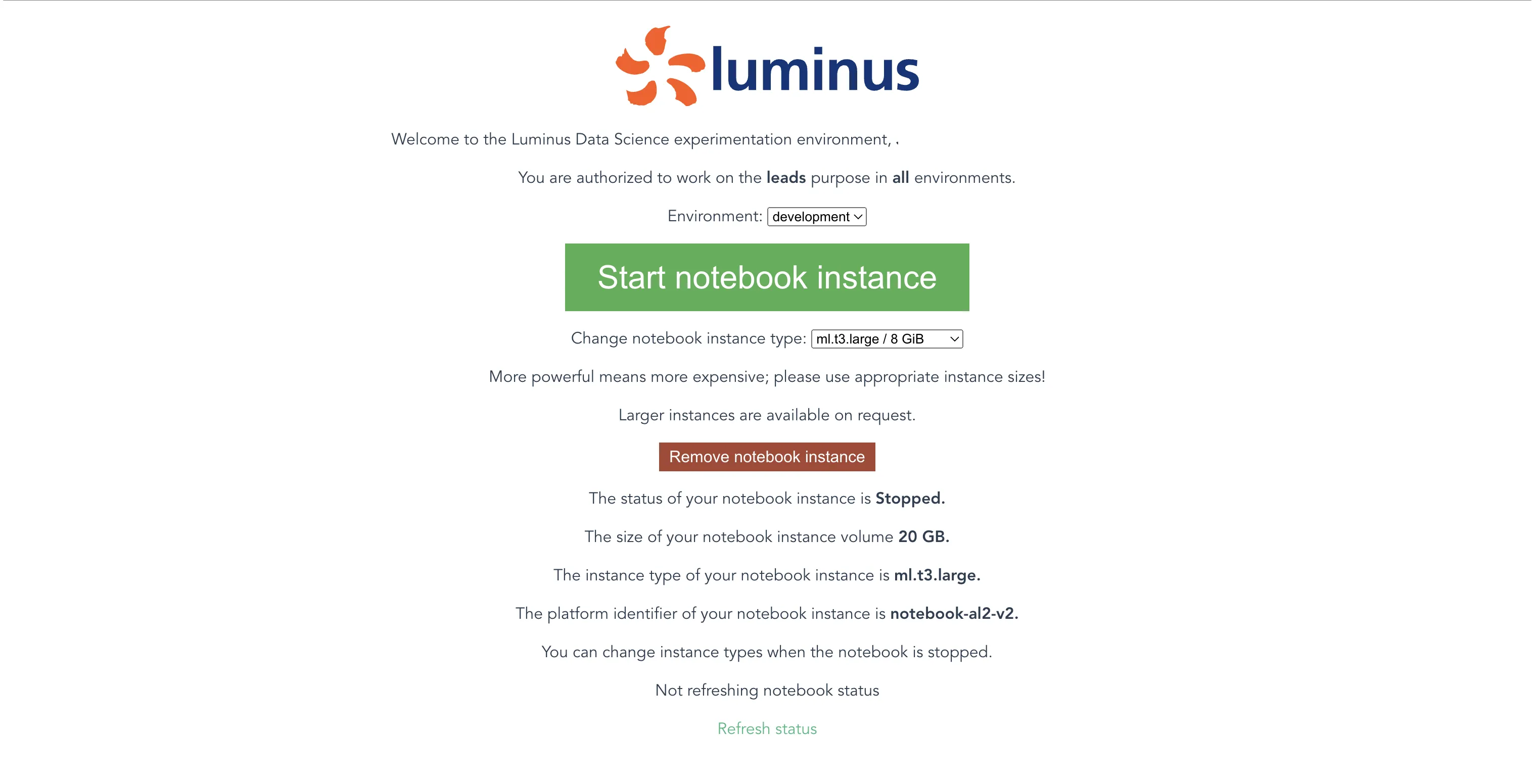
Gitpod as part of the Luminus data stack with Gitpod
Luminus data-teams were able to create reproducible Python development environments, allowing their data team members to onboard and deploy code to production on day one, achieving productivity that feels out of reach for data teams. Luminus were also able to deprecate their previous solution of Amazon SageMaker Notebooks, saving them $36,000 per year, and replace it with Gitpod and Conveyor. With Gitpod, Luminus now has stable and reliable data development environments built around best-of-breed technology workflows and best practices from software engineering, such as git, docker, SSO authentication and fine-grained access control.By leveraging the Gitpod Enterprise deployment model, Gitpod is deployed into the Luminus AWS account and managed by Gitpod. The Luminus platform team spend no time operationally managing clusters of instances, VMs, or Kubernetes clusters, rather they collaborate with data teams to configure their projects, and achieve a one-click getting started flow.
By using single-sign on and AWS credentials that are automated into their data team development environments, pick a resource size, and get to work immediately without touching a single Python dependency or copy/pasting a secret or environment variable. Luminus’ sensitive data is secure in their AWS VPC, and each Gitpod user has fine-grained permissions set so that they only access the data they need.
The Luminus platform team managed to set up Gitpod workspaces as a capability for their data team in just 3 weeks. As a result, the Luminus platform team have now reclaimed over a day a week from supporting the data team with broken environments, and are now already looking to level up again with future capabilities such as Generative AI for their organization.
From SageMaker to an effective data science platform
“A demo shows it all” says Jelle. “Click and open Gitpod (and you’ve already saved 10 minutes on your Python installation with their prebuilds feature, and AWS is set up). Run a notebook with PySpark or AWS wrangler with Pandas. Commit and then CI/CD will do the rest and deploy the code.”
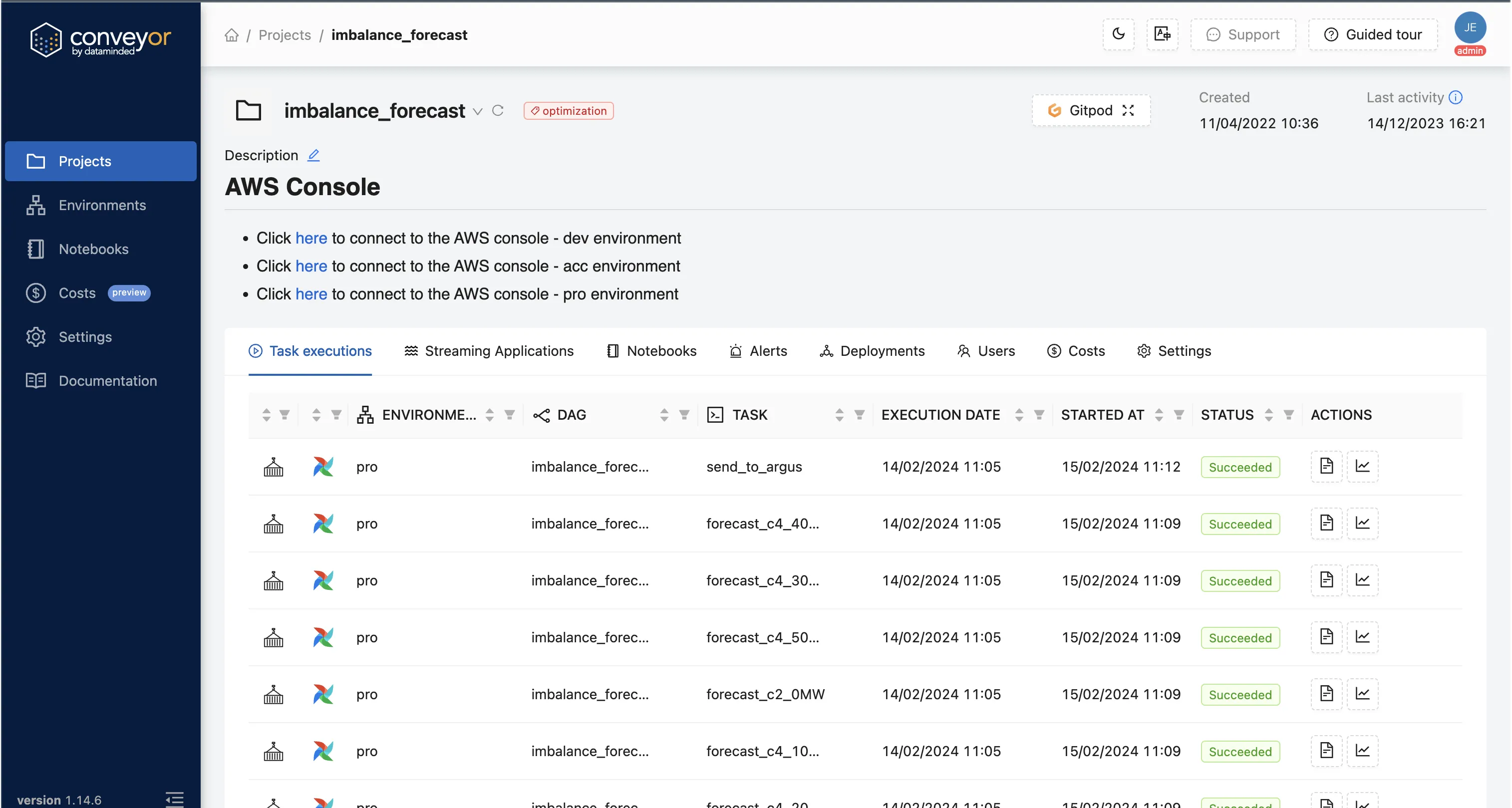 Today, DataMinded’s Conveyor portal includes an integration with Gitpod
workspaces; the Gitpod workspace then uses Gitpod’s OpenID Connect
Integration (OIDC) to connect with AWS and assume an AWS role and grant
access to AWS services and data that that role is permissioned to. When
the link is clicked, the Gitpod workspace is instantly available—already
prebuilt with the VSCode Jupyter extension and able to be customized
with the exact compute and memory needed to effectively perform data
tasks.
Today, DataMinded’s Conveyor portal includes an integration with Gitpod
workspaces; the Gitpod workspace then uses Gitpod’s OpenID Connect
Integration (OIDC) to connect with AWS and assume an AWS role and grant
access to AWS services and data that that role is permissioned to. When
the link is clicked, the Gitpod workspace is instantly available—already
prebuilt with the VSCode Jupyter extension and able to be customized
with the exact compute and memory needed to effectively perform data
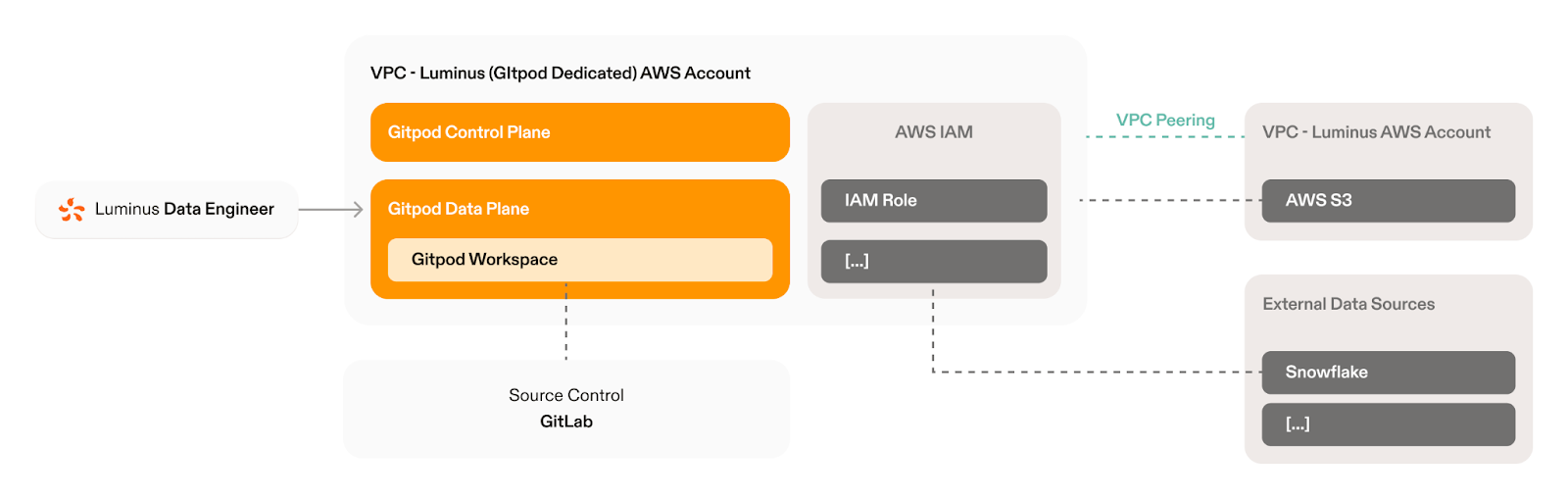
tasks.Using the Gitpod OIDC integration, a Gitpod workspace is immediately connected to the AWS role that belongs to the purpose of that GitLab repository, allowing data engineerings to immediately access all AWS data and services they have been permissioned to, without having to worry about setting up AWS Access Keys, losing secrets, or issues if devices are stolen or lost. All AWS identity and access management (IAM) rules and policies are then restricted within Luminus’ AWS account and fully controlled by their platform team, allowing them to use any AWS service. Through the OIDC AWS authentication, Luminus can then grant access to other data tools such as Snowflake and resources inside their VPC.“That's a big feature: the Gitpod OpenID Connect integration with AWS. We configure workspaces to be able to connect with AWS Glue. You can just run a notebook in Gitpod, and it’s immediately connected to your data.”
Once authenticated to AWS, individuals are no longer locked out of the S3 buckets as they were previously, due to having incorrect VPC endpoint access. Now, with Gitpod Enterprise deployed into the Luminus AWS account and VPC peered with the relevant networks, Luminus can grant fine-grained access to AWS adhering to the “principle of least privilege”. Also by having single sign-on (SSO) configured Luminus controls who has access to their Gitpod instance.“Luminus doesn't allow a VPN for ‘bring your own device’, and most consultants have their own device. Which means those consultants cannot access all of the data system. With Gitpod, the consultants can connect securely through single sign-on and then in Gitpod, they can connect to the data systems.”
With data engineers working directly in VS Code with Jupyter Notebooks, it’s seamless for Luminus data team members to move from what Jelle calls the “experiment phase” to the “build phase” without any additional environment setup. In the past, when individuals were done experimenting in notebooks, they had to switch to an IDE and start from scratch by copying code from the notebook to the IDE. By having those two phases closely coupled in Gitpod, better development practices are encouraged from the start. Data engineers and data scientists can directly write proper functions in their IDE and import those in notebooks so that they don't have to copy and paste code later when they start industrializing their machine learning models.“The structure of notebooks does not incentivize good software design patterns though. So once you are done exploring, a proper IDE is the right tool for the job.” — Luminus Data Engineering Manifesto
Gitpod workspaces come with the git command line and VS Code extension already installed, making it easy for the data teams to make good use of VS Code and practice source control hygiene with Git, using a Git GUI if they prefer. The Luminus data team does not need to configure their command line, or know anything about system administration or Linux to get set up with a working development environment.“Data scientists are our colleagues, not our mortal enemies. Data engineers and data scientists share a common technology stack, yet they often play a different role in the organization. We work together and see the best results emerge in cross-functional teams.” — Luminus Data Engineering Manifesto
If you want to learn more about how to get your data engineering teams setup with Gitpod, or CDEs in general, reach out to a member of our team!“Teams just want to implement their business logic. There were lots of challenges with Windows machines and WSL. And not all team members are Linux experts, know how all the Python build tools work, know how to work best with virtual environments and so on. It was a hassle and we didn’t need them to become infrastructure experts.”
 The innovative project is implemented using Gitpod’s Enterprise
solution, built on top of Amazon Web Services (AWS) using AWS-designed
highly performant AWS services such as Bedrock. The composability on AWS
is crucial to deliver the highest level of flexibility for Luminus. It
allows Luminus to select the best-of-breed components they need, which
will work seamlessly and reliably straight away, thanks to Gitpod and
the high levels of service AWS has. Due to AWS, the onboarding of new
developers takes as little as a few minutes, compared to months
previously. With the Gitpod solution, built on AWS, Gitpod can scale
computational and storage resources to accommodate Luminus's goals.
The innovative project is implemented using Gitpod’s Enterprise
solution, built on top of Amazon Web Services (AWS) using AWS-designed
highly performant AWS services such as Bedrock. The composability on AWS
is crucial to deliver the highest level of flexibility for Luminus. It
allows Luminus to select the best-of-breed components they need, which
will work seamlessly and reliably straight away, thanks to Gitpod and
the high levels of service AWS has. Due to AWS, the onboarding of new
developers takes as little as a few minutes, compared to months
previously. With the Gitpod solution, built on AWS, Gitpod can scale
computational and storage resources to accommodate Luminus's goals.
