Dev environments as code
Imagine that only a decade ago system administrators deployed, configured, and maintained software systems manually. Doing so burned an endless amount of their precious lifetimes and energy.
Today, in the age of microservice architectures, systems have become even more complicated. Trying to maintain operations and deployments by hand isn’t optional anymore. These days we do “DevOps” or “Infrastructure as code”. We have learned that describing a software system in a declarative and formal way is mandatory to deploy applications automatically and continuously.
What about our dev environments?
While we have automated deployments of our applications, most of us don’t apply the same techniques to developer environments, yet. Instead, on-boarding a new team member on any non-trivial project usually is a multiple hour (if not days) exercise.
It often goes like that:
A new developer gets pointed to the readme
Reads lengthy, mostly outdated setup procedure
Installs requirements on the developer machine, updates/downgrades versions, etc.
Tries to run the build … waits 20 minutes
Build Fails. Try figure out what went wrong.
Asks colleague. “Oh, yes. You also need to do X & Y”
goto 3
After many iterations at some point, the build somehow works. You don’t know why, but that doesn’t matter now. Of course, you are not updating the document, as you are not sure and don’t know how you ended up with a working setup. Is that current state even reproducible? So if you update the readme, you better only add what you figured out. You don’t dare to remove parts that you didn’t understand or skipped because they didn’t work for you.
Too bad the setup only worked on first glance. During the following weeks, you will have to solve smaller issues here and there and add some tools that were not listed. Maybe debugging doesn’t work yet, or you don’t see the sources from upstream dependencies. Eventually, it smoothes out. Only when a colleague changes something in the requirements, it usually takes two days until the whole team has noticed and changes their environments accordingly.
Unfortunately, the pain doesn’t stop here.
It works on my machine
You probably know the famous phrase “It works on my machine”? The situation when a bug only appears on one machine and is hard to reproduce on others? That feeling when a bad thing happens in production, but you can’t reproduce it locally? Not very surprising, though, as long you are running the code on a different platform based on a different setup.

Going back to fix something on an old branch
Another pet peeve is when you need to fix something on a maintenance branch. Fixing the actual bug could have been so easy, as you know how to fix it. However, before you can call it done you need to be able to build and test that old beast. This is costing you an endless amount of time.
Tinkering with a six months old technology stack can be so annoying. You have to deal with all those old libraries and versions of them. However, you still have to make it work somehow.
 Photo by JESHOOTS.COM on Unsplash
Photo by JESHOOTS.COM on Unsplash
All this suffering can end if we applied the ‘infrastructure as code’ idea to our dev environments, too. Why not make dev environment setups automated, reliably reproducible, and versioned by writing them down in an executable format and checking them into the project’s source code repository?
Dev environment as code
After all, dev environments are often even more complicated than the runtime application they are used for. You typically need to add all the development tools such as build tools, compilers, linters, and a decent editor / IDE on top of the runtime requirements.
If you want to ensure that changes don’t break anything down the line, everybody needs to code, run, and test on the same environment the CI builds run on.
So let’s please stop polluting our readme files and start writing setup instructions down formally, so they can be executed.
Dockerfiles
Docker files are a pretty neat way to describe a developer environment. Imagine you want to add something like ‘asciidoctor’ to your project’s toolchain. You could just add the following line to your dev environment’s Dockerfile:
RUN apt-get install -y asciidoctor
Once you push the change to the repository and the Docker image gets updated (automatically), all team members have the new tool in their developer environment. We need to get to coding with a single click.
 Photo by Clément H on Unsplash
Photo by Clément H on Unsplash
Automated IDE Setup
The Docker approach gets a bit clumsy if your development tools have a UI such as a desktop IDE. You can package them in Docker, but you have to expose the IDE’s UI through X11. Another alternative is to go with a terminal editor like vim, but of course, that is not an option for most of us.
Some desktop IDEs have tools that allow automating setups. Eclipse, for instance, has a tool called Oomph. Oomph allows you to declaratively describe an Eclipse IDE including plug-ins, configuration and even workspace setup. (i.e. Git information).
By far the best option is an IDE that runs in browsers, like the new Theia IDE. Theia is open-source under the Eclipse Foundation. It can be seen as VS Code that runs on browsers and desktops and is a bit more customizable.
For a simple Docker-based dev environment you could add Theia to your Docker image. It offers a full IDE including terminals to your workspace image.
The next step would be to treat your developer environment as some serverless function which you only spawn when needed and forget about when done. The online service Gitpod does exactly that.
It integrates with code hosting platforms such as GitHub. It eliminates all the tedious transitions by automating them. You see code on some website and want to give it a spin in a real dev environment? Gitpod does everything it can to get you there with a single click. It lets you provide custom Docker files or Docker images and runs Theia IDE.
Summary
Applying the lessons learned from DevOps to our development setup can save us so much precious time and energy. ActiveState’s Developer Survey 2018 underlines this with some numbers:
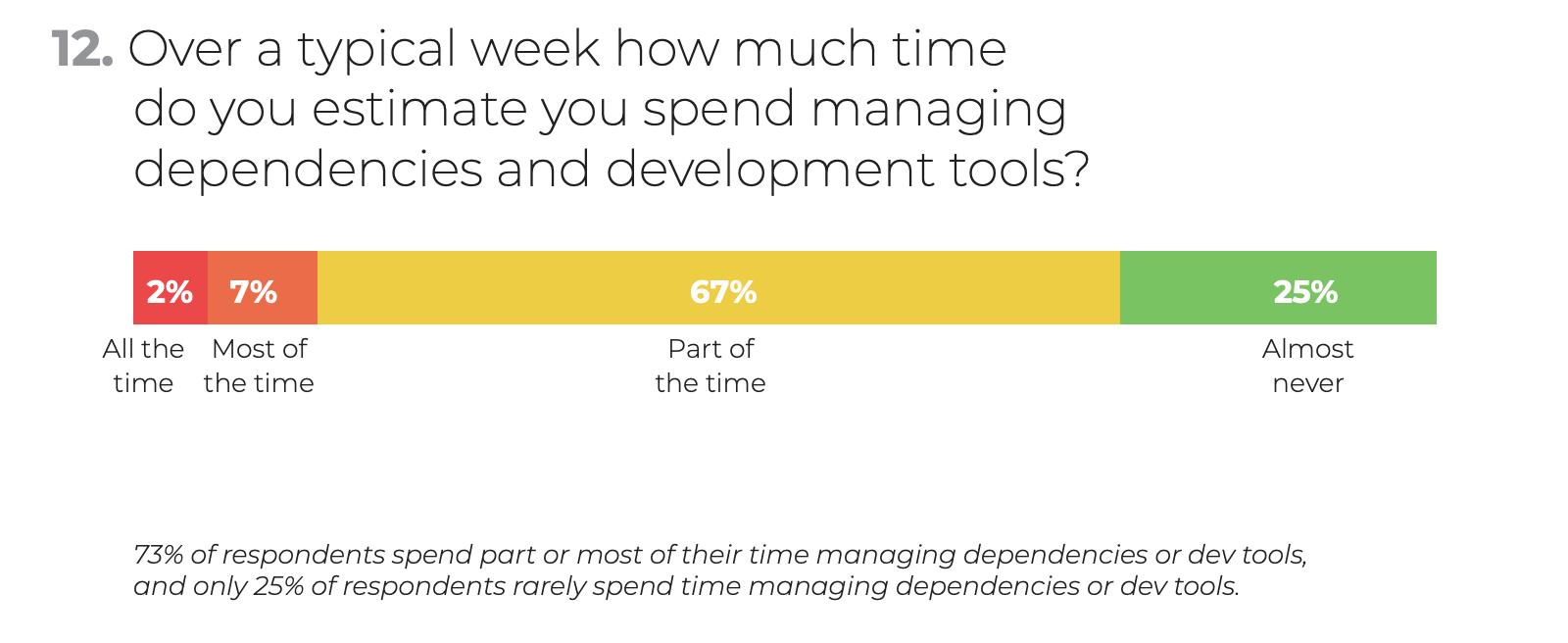
Do we really need to welcome new colleagues or contributors with a painful on-boarding experience? Let’s skip the prose in the readme and write code to have our dev environment setup automated, reproducible, and versioned.
