The K8s chasm of doom: How 'configuration drift' with Kubernetes can accidentally erode our developer experience
Both Kubernetes and Docker have been on the tech scene for over a decade, so I wouldn’t blame for assuming the developer experience of using them is a solved problem. However, as I have recently been speaking to many platform teams, I’m continually reminded how many companies are struggling to fit all the pieces of the cloud native puzzle together to form a slick developer experience with fast feedback loops, all the way from local development to production.
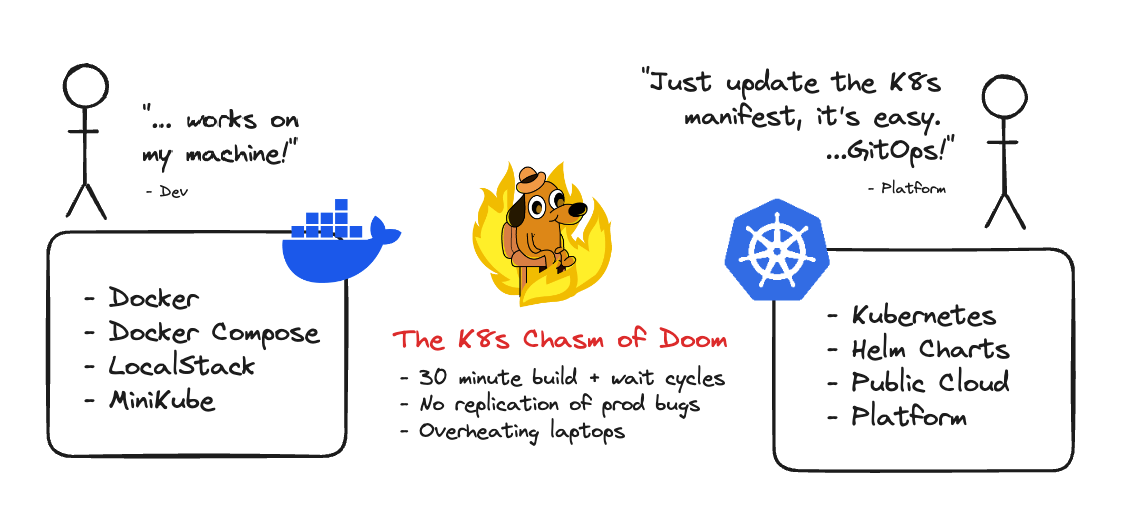 Caption: The “K8s chasm of doom”—which emerges as a result when Kubernetes configuration and developer configurations drift apart.
Caption: The “K8s chasm of doom”—which emerges as a result when Kubernetes configuration and developer configurations drift apart.
A principal challenge in building a good developer experience around Kubernetes is wrangling the challenge of “configuration drift”. When we’re not careful, a very deep chasm emerges between our infrastructure configurations like our Kubernetes manifest files, ConfigMaps Helm charts and our local developer environment configuration using Docker or Compose. This chasm makes replication of issues almost impossible, forcing us to run 30 docker containers on our local machines inside Minikube, or suffer agonizing 30 minute build times pushing images and waiting for preview environments.
If you’re lucky enough to have not seen Kubernetes configuration drift play out in real-time, today I will tell you a fictitious—yet all-too-real—story. You can see this story as a cautionary tale for those brave enough to embark on their valiant journey into the world of Kubernetes. Or, for those amidst these pains, you can see it as a cathartic way to explain to your loved ones about your woes. Or, even better yet, use today’s story to convince your boss about why to invest in your developer experience to claw out of the chasm of doom! Let’s get into it.
Introducing GovApp
After six months of grinding on job applications, you just landed a new job as a full-stack developer at an exciting new start-up called GovApp. GovApp is a platform for local governments which is going to revolutionize online government services for its citizens. On your first day you meet up with your new boss, head of engineering, Eva and your new colleague Pauline, a Platform Engineer. Pauline has worked in an operations background before, so she’s pretty handy at working in the cloud. GovApp being a start-up, there’s a ton of work to be done.
It all starts with a single container
The GovApp platform starts first with a simple front-end application landing page. You set to work on detailing the GovApp services for their website. For simplicity you decide to run the application as a simple node application and web server so that you can use React.
 Caption: The GovApp Landing Page, built in React.
Caption: The GovApp Landing Page, built in React.
“It looks great!” says Eva marveling at the locally running website over your shoulder. “If you get this deployed somewhere, I can help you test!”. You speak to Pauline about how to deploy the application, and Pauline suggests using Docker. With a quick bit of reading and copy/pasting from StackOverflow you’re up and running using Docker.
FROM node:20
WORKDIR /usr/src/app
COPY package*.json ./
RUN npm install
COPY . .
EXPOSE 3000
CMD ["node", "main.js"]Caption: The GovApp Dockerfile.
Pauline does a bit of magic in the cloud to deploy the container and voila!
Keeping everything up-to-date is easy. Each time Eva raises a bug, you pull down the latest code, make the changes, build the Docker image, push and you’re back in production. Each iteration takes no more than ten minutes from bug raised, to fixed in production. Everything is great, and life is good!
It’s time to go multi-container (with Docker Compose)
After multiple rounds of review, Eva is happy. “It’s time to get started on the GovApp application” Eva remarks in a morning standup. After a quick chat with Pauline, you figure that the best way to configure the back-end is to split the application architecture into front-end and back-end. Luckily though, you can continue using Docker as before. If you need the frontend you spin up the front-end container, and the same for the back-end.
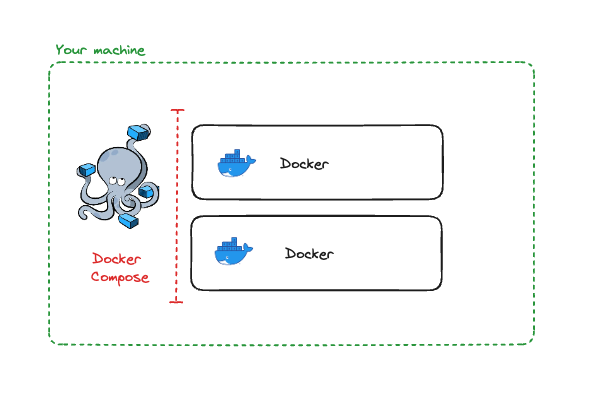 Caption: The GovApp architecture running two Docker containers.
Caption: The GovApp architecture running two Docker containers.
After watching you during a code review running separate docker commands on your machine for each container, Pauline suggests that you setup a simple Docker Compose configuration to launch and test your application locally with a single command. Sweet! You hadn’t heard about Docker Compose, but it sure works well. This whole “cloud native” thing is easy!
version: '3.0'
services:
front-end:
image: front-end
build:
context: ./front-end
dockerfile: Dockerfile
ports:
- "3000:3000"
back-end:
image: back-end
build:
context: ./back-end
dockerfile: Dockerfile
ports:
- "3001:3001"Caption: The GovApp Docker Compose configuration.
Preparing for scale - going “full microservices”!
A few months go by and GovApp is flying. With many customers signed up, Eva decides it’s time to think about scaling the engineering organization—and goes out to start a hiring drive. In anticipation of the steep onboarding curve new joiners face, you agree to start to break down your back-end application into microservices. Each team will take an individual service, and manage the experience, end-to-end using the “you build it you run it’ approach.
As new engineers onboard, Pauline shows each team the same configurations for their local setup, including how to configure the cloud to run their services. Each team copies and pastes some infrastructure definitions that Pauline has created, and configures their own pipelines and automations to run their containers in production—awesome! Before long, each team is up and running in production with their own services and a similar setup running Docker Compose locally for each service that they need—deploying to the cloud.
Several months go by, and everything is going well. GovApp is growing and each of the teams seem to be settling into their work.
However, one day, as Eva is reviewing the onboarding of the fifth team into the organization she notices that something is off… It seems that every time GovApp adds a new team into the organization it takes them nearly three months to get a basic service into production. “But, how can this be!?” Eva asks, confused. “Haven’t we been running containers in prod for years? Shouldn’t a new service be deployed in a day, or a week? What’s going on here?”
The architectural approach that GovApp has taken up until this point has been for each team to build and manage their own infrastructure and pipelines. This was the fastest way to get the teams up and running, explains Pauline. Eva heard about the idea of “Platform Engineering” at a recent conference, and urges the team to look into how they could run a simpler, consolidated setup that would allow new teams to onboard quicker and deploy services faster.
Enter Kubernetes
Building ontop of Eva’s ideas of Platform Engineering. Pauline suggests GovApp look into Kubernetes to orchestrate their microservices. She’s heard that Kubernetes is the platform of choice for organizations around the world.
“It’s developed at Google scale! Kubernetes will give us everything we need to run business applications at scale! Best of all is that we totally avoid any vendor lock-in as we’ll be running purely cloud native”.
Eva is sold! Kubernetes it is!
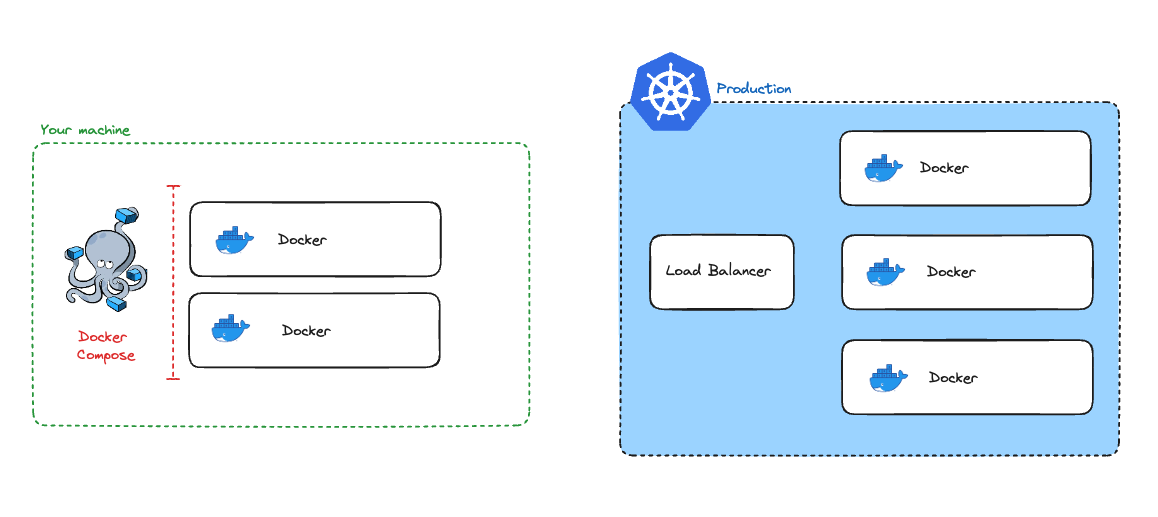 Caption: The GovApp local and remote architecture.
Caption: The GovApp local and remote architecture.
After several months thrashing through the Kubernetes documentation, and getting everything configured, each team now pushes their container images, and Kubernetes picks those up to manage the containers in production.
Now, GovApp no longer needs to share infrastructure definitions with each team, instead they need one update to their infrastructure configuration, and can deploy by updating their container image. GovApp has reached the golden age of Cloud Native! Or, so it seems…
The creep of Kubernetes configuration
After several months of no issues, you get a phone call whilst out. It’s Eva. “The app is down! We need to fix this—quick!”. You find a quiet corner of the restaurant, pull out your laptop and do some quick checks on the latest version of the application. “Works on my machine!” you tell Eva, before hanging up to investigate further.
 Caption: The PagerDuty alert for a P1 incident.
Caption: The PagerDuty alert for a P1 incident.
“Well, this doesn’t really make any sense” you think to yourself. You check the deployed commit of the application(s) in production, and again pull fresh code from GitHub to startup your Docker container again. “Nope, seems to still work.” Confused, you dive into the cloud account. Whilst the cloud is usually Paulines area of expertise, you figure: “how hard can it be?”. 30 minutes of thrashing in the cloud interface and you finally stumble on a clue in some logs. It seems the application is running, but it looks like it’s inaccessible to the load balancer.
 Caption: Eva is pushing for updates on the incident.
Caption: Eva is pushing for updates on the incident.
At this point Pauline joins the incident chat.
“Ohhhhh!” Pauline types, ominously.
“We refactored our previous load balancer configurations, but forgot to update the container definitions!”. We’re now expecting the application to be running on a different port and path but we didn’t update our app or Dockerfile! Pauline updates the configuration in the app repo, pushes the changes and verifies everything is working in a test environment, before pushing to production.
Over the course of the next few months, this situation keeps reoccurring.
Changes made to local docker configurations keep being misconfigured, and Kubernetes configurations keep drifting from their local counterparts. Often these configuration mismatches get caught before they land in prod, but every couple of weeks misconfiguration is causing production outages…
Climbing out of the K8s chasm of doom
I hope through hearing the story of GovApp, you can see how when adopting Kubernetes, it is very easy for configurations to start to drift. Our upstream Kubernetes installation runs on Kubernetes manifest files and configurations, and relies on integrations with the cloud. Whereas our local configuration is using Docker Compose configurations that are often fundamentally different.
It’s this configuration disparity that gives rise to the “K8s chasm of doom”. We end up with infrastructure defined in one way, often by our platform teams, with our developers using local configurations that are not replicas of production. What begings as simple configurations soon becomes increasingly complex and the risks of the configuration drift can become a risk to our business.
Caption: The “K8s chasm of doom”—which emerges as a result when Kubernetes configuration and developer configurations drift apart.
The purpose of todays post was not to give solutions just yet (actually, solutions will be covered in the the nex blog post!) but to showcase in an accessible way the challenge that emerges slowly over time with Kubernetes configuration drift. We don’t often mean for our configurations to drift in this way, it happens slowly over time as our systems become increasingly complex.
If you’d like to hear not only about the challenges of Kubernetes configuration drift, but importantly learn how you can solve it, Gitpod is hosting a webinar on February 15th where we’ll discuss through how to solve these challenges in-depth. Do also keep an eye on our blog, as we’ll be posting some additional blogs talking about solutions to Kubernetes configuration drift!
